

How To Flush Pages Out Of Google En Masse
This column is designed to help SEOs and webmasters fix common SEO problems on their own website.
Google gives you a few ways to “deindex” pages. That is, kick pages out of their index. The problem is, despite some serious speed improvements in crawling and indexation, they’re pretty slow to deindex and act upon canonical tags.
We know the <meta robots=”noindex”> will punt URLs out of the index, but you have to wait for Google to crawl them. Our server logs show us that Google doesn’t always act quickly even though they crawled the page. So much for directives!
We also know that Google Webmaster Tools has a “remove URL” tool, but the sucker doesn’t let us request bulk removal. Matt Cutts also told us not to “overdo it on the removal tool.”
Robots.txt won’t necessarily remove pages from the index. It only keeps Google from crawling the pages. An uncrawled page can still index. You’ll even see this adorable snippet in most cases:

Pages with a 404 response will eventually get a page deindexed, but only after Google has come a few times to verify the page is still gone. As they’ve reminded us, “Google has a big memory;” the faster way to remove a page with a response header is using a 410 (page is gone) instead of a 404.
The big problem with all of these methods? They’re slow. Not to mention, some aren’t very scalable.
If you’re doing work and want faster results, I came up with a trick that seems to work a bit faster.
- Round-Up All The Pages You Want Deindexed
- Add The <meta robots=”noindex”> Tag
- Create an XML Sitemap with only these URLs
- Submit To Google
- Wait
- Remove The Sitemap When You’re Done
Disclaimer: I can’t prove unequivocally that this trick works. While it seems to show results, (and logically, why shouldn’t it?), I can’t say for certain that the XML sitemap is the driver, and not Google’s natural bot-returns. But even if it doesn’t work, it’s still a great way to monitor the deindexation of files.
Let’s Review The Steps
Step 1 and step 2 are pretty self-explanatory. Here’s an example – we recently had a client testing dynamic landing pages. He had no idea that the 30,000 “test” pages he created with a click of a button were available to Google. After seeing a sudden spike in GWT, we caught it – but it was too late. Google had them, and wouldn’t likely forget them as quickly as they learned about them.
In this case, it was a fairly simple implementation getting <meta robots=”noindex,nofollow”> on the dynamic template, but these pages were deep in the index. Google had to come back to all 30,000 pages, and that was going to take a long time. We wanted to close the path to these pages so users didn’t find them, which only adds to the time it would take Google to revisit these pages (we’ve severed the crawl path).
In this case, there was a unique folder structure – www.client.com/lp/test/dynamicpage1. By letting Screaming Frog crawl the site (and a little prodding to get them to focus on the right location), we were able to gather up all the “text” URLs fairly quickly. If you don’t have a unique URL footprint, perhaps there’s a keyword or piece of unique code that can call these pages out. The custom filter (Configuration > Custom) lets you breakout pages with a certain keyword anywhere in the source code.
It’s possible you’ve crawled many pages outside of just what you were targeting, so you may need a little clean up in Excel. Export and filter in Excel as needed (some of you might be able to set up regex with Screaming Frog’s “include” or “URL rewriting” features to create custom crawls and skip this step). Then simply reupload the now-scrubbed list of URLs using Screaming Frog’s list mode:
Next, simply upload your new XML Sitemap. Do yourself a favor and give it a descriptive name. Instantly you’ll see a “submitted” count (blue line). Now you wait.
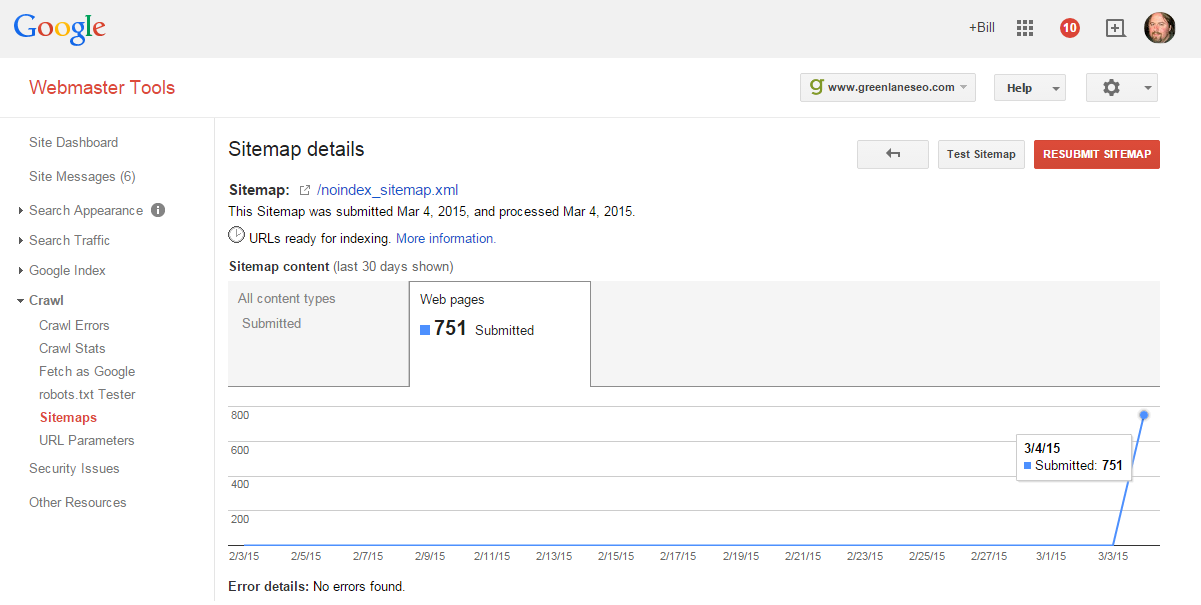
In a few hours you’ll get your first indexation snapshot. Now, I really don’t know how accurate this “red” number is – I tend to take all Google Webmaster Tool’s data with a huge grain of salt. But, it’s the trend we’re really interested in here.
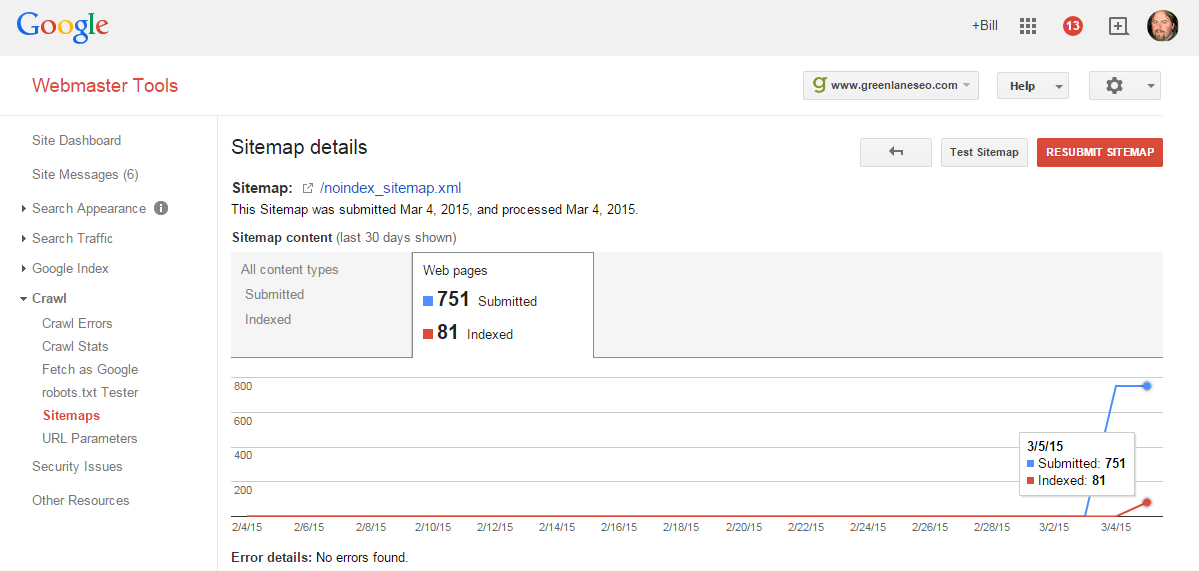
According to this, of all the pages I don’t want Google to index, they have 81 currently indexed (at least that’s how I read it).
This suggests that Google isn’t necessarily quick to act on the new URLs introduced to them. If they were, I’d have zero-indexed pages instead of 81. In other words, Google says, “thanks for the pages – here’s your current indexation data. I’ll take a look at them later…” Why do I believe that? Simply because the <meta robots=”noindex”> directive that’s on all these pages haven’t been honored. Now we sit back and watch the trend.
Time For A Check-In…
It’s been a few days, time to log into Google Webmaster Tools and see how our little project is coming along:
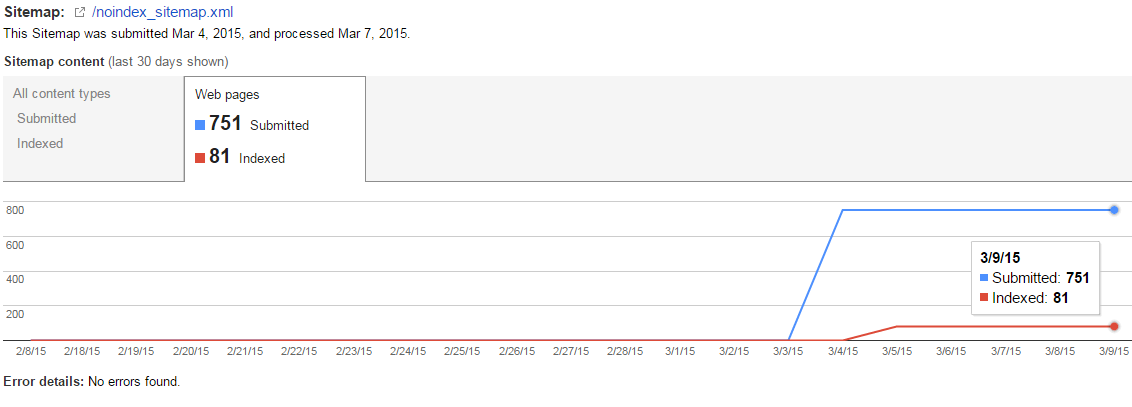
Unfortunately, Google has still not acted on the 81 URLs that are in the sitemap marked with a <meta robots=”noindex”>. Don’t be discouraged – this isn’t uncommon.
Time For Another Check-In…
Now it’s been another 4 days, and we’re finally starting to see some activity. 10 pages nixed.
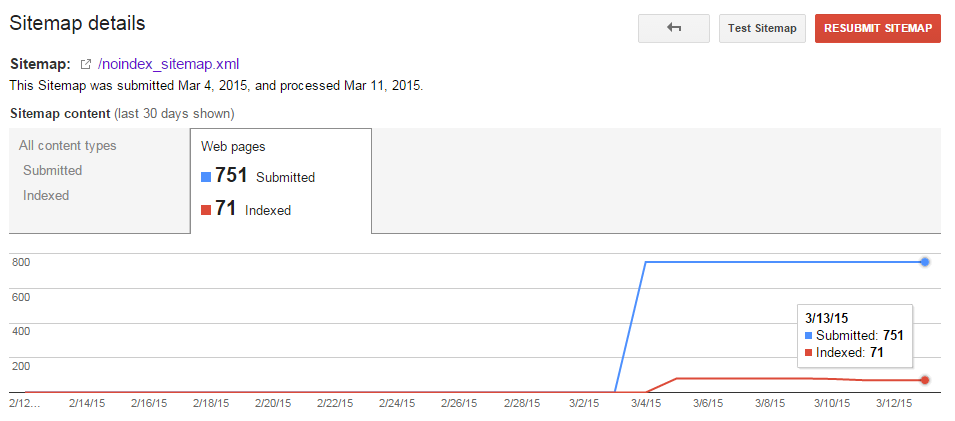
And Another Check-In…
It’s been another 5 days, and we’re down a few more pages.
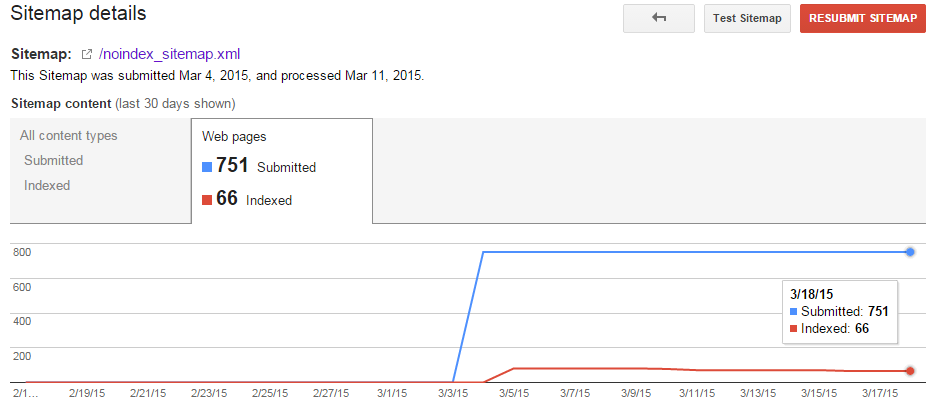
Last Check-In…
14 days later, and we’re down even more pages. This is working as expected, so I’m going to wrap up this post. I think the trend speaks for itself.
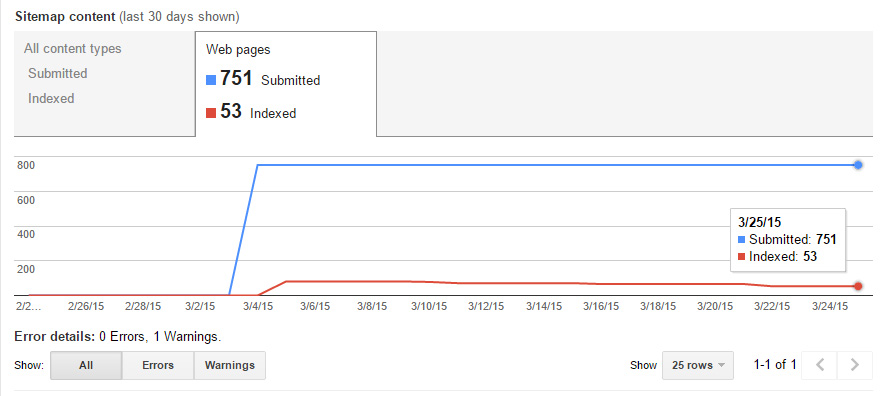
Summary (Last Step)
It’s important to keep watching this. Once you get down to zero pages, clean up your campaign. Remove the sitemap from your site, and remove it from Google Webmaster Tools. You’ll notice your index status eventually reflecting this as well. That’s all there is to it!





