

Improve SEO by Auditing and Fixing Canonical Tags (and How to Do It)
How Do I Find My Canonical Tags?
- Crawl your website with Screaming Frog to get data on all your website URLs. Let the crawler discover all the pages you have open to search engines. (Details)
- Once done, export through the “directives” tab, and filter “canonical”. Click “export”.
- With Excel, you can add =IF(A4=B4,”Equal”,”Not Equal”) in a column to quickly identify which canonical tags are properly implemented.
Like Technical SEO? You May Also Like:
- How To See If Blocked Pages Are Indexed
- How To Flush Pages Out Of Google En Masse
- Find and Fix “Index Bloat” SEO Issues
The canonical tag can be a blessing or a curse. Living in the <head> section of your webpage, its purpose is to suggest to search engines the proper canonical page. The “canonical” page is the original page, or the page you want to represent your “main” document.
Notice above I said, “suggest to search engines.” That’s because Google and Bing won’t take this tag as a directive – instead, they’ll consider it a hint. This is a very important concept, as we see many times where Google doesn’t follow the hint (and should have), and vice-versa. These miscalculations by Google are why SEOs need to understand and monitor canonical tag implementations.
Here’s more on the canonical tag definition: http://googlewebmastercentral.blogspot.com/2009/02/specify-your-canonical.html.
So What’s The Big Deal?
(If you already know how canonical tags work, you can skip this section.)
The reason Google doesn’t accept the canonical tag as a directive is probably because they know many webmasters can easily screw it up (eg, syntax, implementation, etc.). If you have a massive database-driven eCommerce site, and you’ve tried to get a developer team to implement canonical tags, you’ve seen how it can ultimately launch with a ton of unexpected results. The best intentions don’t always equal proper implementation.
Examples I’ve seen: Through templates, products were suddenly “canonicalizing” to the homepage. Or, page 4 of a collection suddenly canonicalizes to page 1 of the collection. Or, duplicate content self-canonicalizing to themselves instead of the proper URL.
Crazy, random results are always likely if not implemented and QA’d properly. The bigger the site, the harder the QA process. When the tag was announced in February of 2009, I worked for one of the largest eCommerce platforms at the time. We wanted to be first to offer this, and we rushed it out – with many, many problems. I’ve always had a love/hate relationship with this tag.
[su_newsletter_email]
Also, in the beginning, it almost seemed as if Google took their time responding to the tag. Logs would show visits over and over again, but the tags would never take. Then on one random visit, boom! As if Google just ‘clicked’ on what we were trying to show them.
This feels like less of a case today, but it’s still prevalent. Patience is a must. But the most frustrating thing – sometimes Google doesn’t honor the canonical tag at all, even when it makes all the sense in the world to do it. I’m currently working on a site with 1.5 million indexed URLs. Only a third of the pages are true canonical URLs, so there’s a lot of duplicate content (thus, index bloat and crawl waste). The canonical tag is on correctly, but Google just hasn’t accepted it yet. It’s been 6 months. In Google’s algorithmic infinite wisdom, it appears we have to do more to get this to influence them.
The bottom line: The canonical tag is far from perfect. It’s that imperfection you, as an SEO, want to plan for.
How To Audit Your Canonical Tags
You’re going to need two things – Screaming Frog (if you have a large site, the free version won’t cut it), and a spreadsheet.
Step 1: Crawl your entire site with Screaming Frog. Give yourself a wide-open crawl so you can get the big picture (to mimic Google). Under configuration > Spider, I typically respect noindex, but force SF through rel=”nofollows”. I also don’t respect canonicals because I want to capture all the duplicate content.
Once done, export through the “directives” tab, and filter “canonical”. Click export.
You’ll get a shiny new Excel file, that after cleanup, will look something like this (click for larger image):
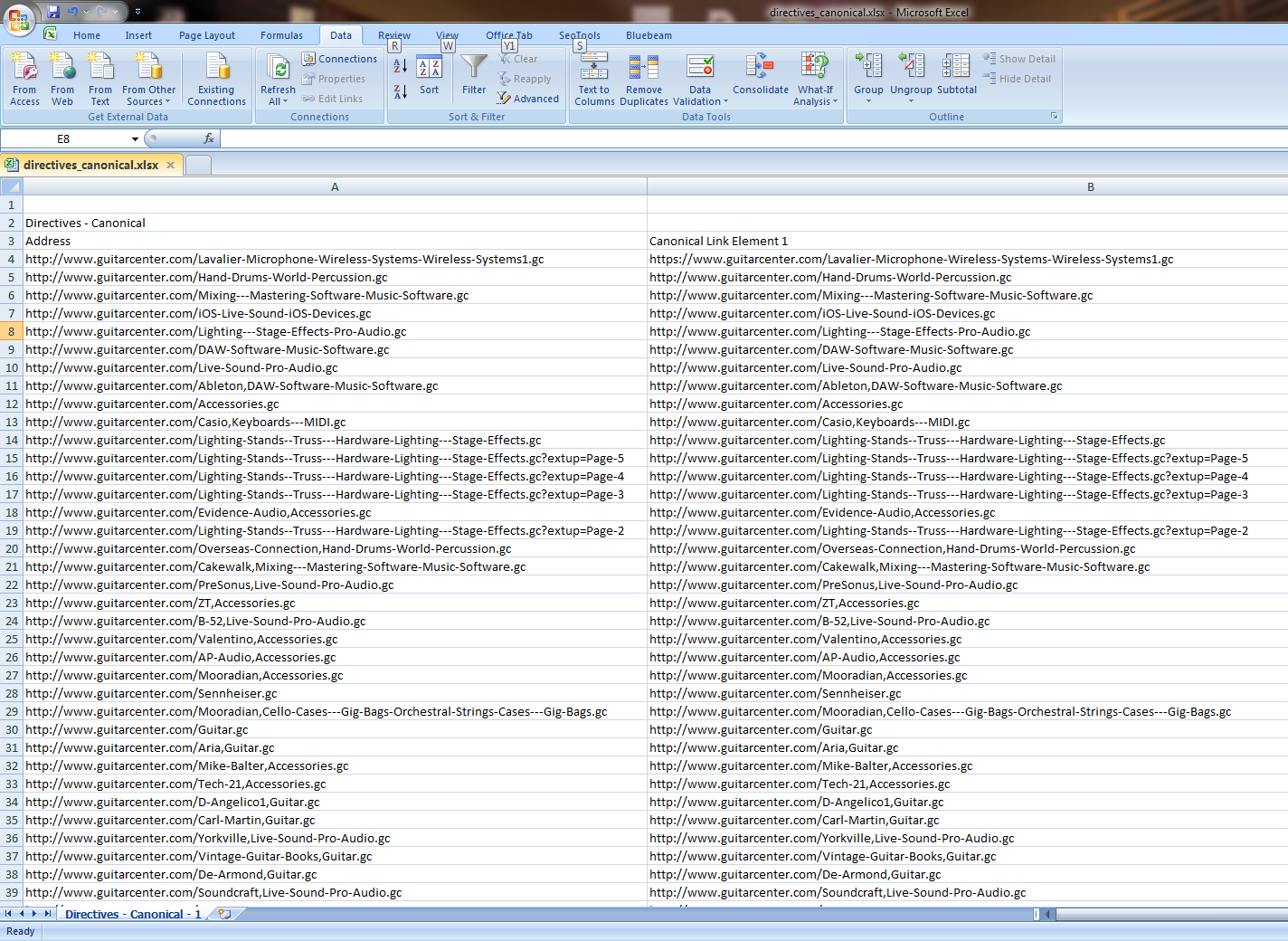
Step 2: Let’s compare column A to column B, and see where the mismatches are. The magic formula to paste into column C is:
=IF(A4=B4,"Equal","Not Equal")Next, sort to view only “Not Equal”. You’ll get something like this (click for larger image):
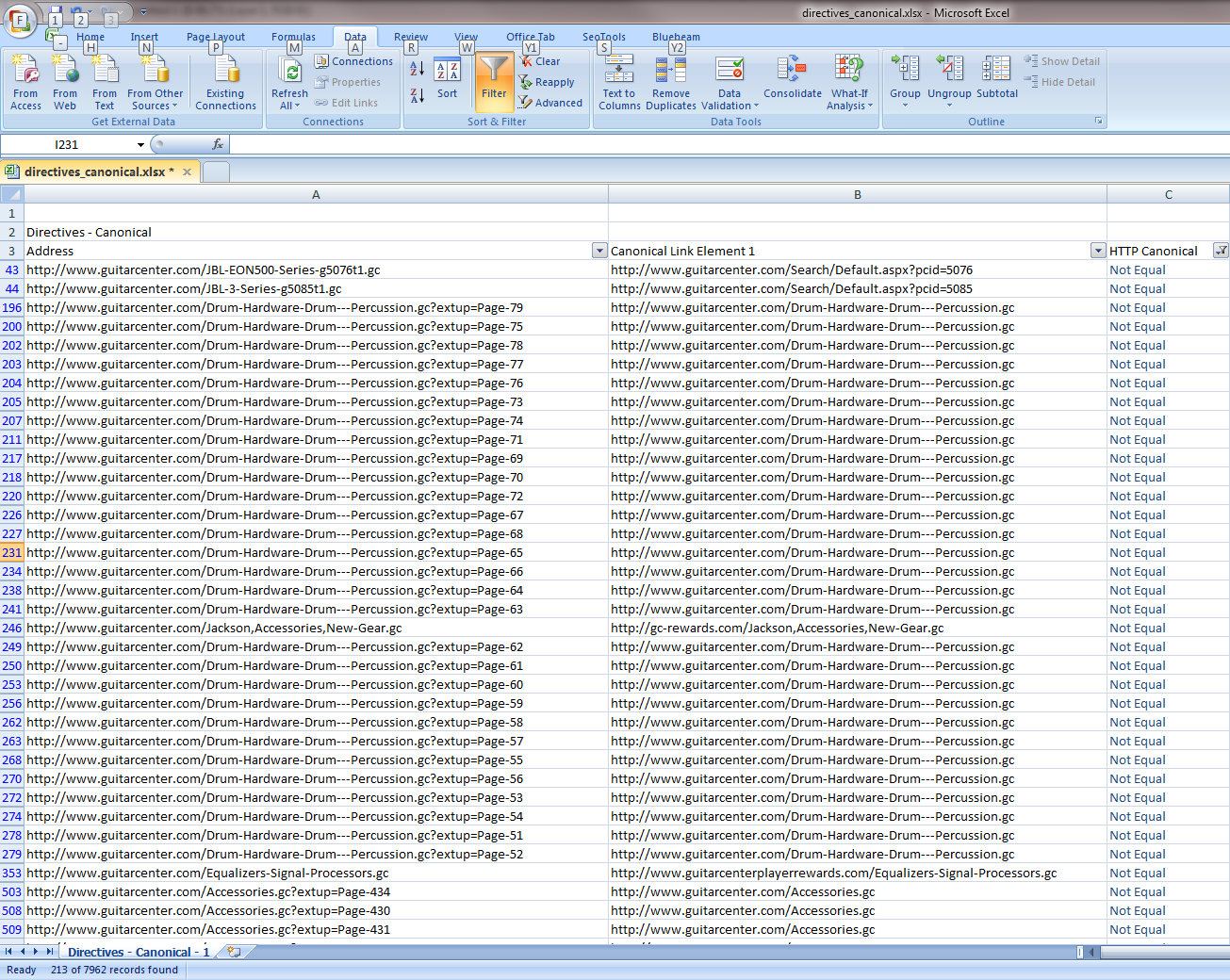
Let’s examine the first result. The spreadsheet tells us this page: http://www.guitarcenter.com/JBL-EON500-Series-g5076t1.gc has a canonical tag for this page: http://www.guitarcenter.com/Search/Default.aspx?pcid=5076.
So in other words, the webpage is telling Google not to index this page:
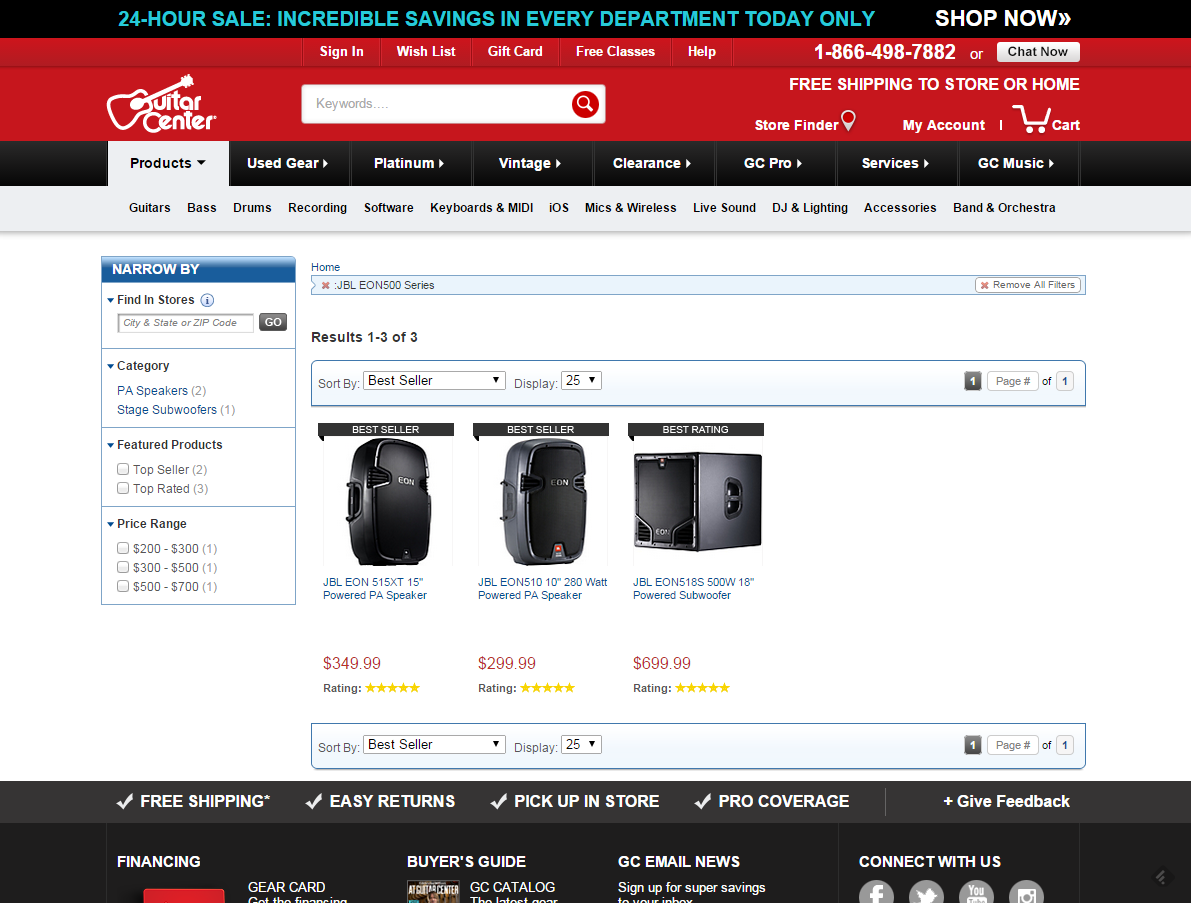
But they should instead index this page:

If Google decides to follow this canonical tag, that would be bad. So I checked to see if http://www.guitarcenter.com/JBL-EON500-Series-g5076t1.gc was indexed. It’s not. In this case (unless there was a bigger reason I’m not privy to), this is a case of a flawed canonical tag implementation.
Reasons Why Google Will Ignore The Canonical Tag
Throughout this article, I spoke about Google reserving the right to ignore your canonical tag when they believe it’s best to do so. But, there are some specific reasons they will ignore your tag. Such as:
- Canonicalising to the wrong URL. (This has been mentioned.)
- Broken canonical URL. (If the code is wrong, Google is not very forgiving.)
- Canonical loop. (If the canonical tags are sending Google in a loop, they’ll disregard the tag.)
Canonical Tag vs 301 Redirect
A quick, relevant comment: I always urge clients to do 301 redirects instead of hoping the canonical tag works. Google says they treat canonical tags just like a 301 redirect, in that it passes the same amount of PageRank. Canonical tags are sensible default solutions – or safety nets – for a website that is difficult to code on, but in my opinion, given the option, a 301 redirect is always the preferred SEO method.
This is a relatively easy process to spot outliers. If you have any questions or want to know more about canonical tag best practices, let me know on Twitter!





